Automated Validation for all of the Apache Hadoop Ecosystem
At Hortonworks we are constantly striving to achieve high quality releases. HDP/HDF releases are deployed by thousands of enterprises and are used in business critical environments to crunch several petabytes of data every single day. So maintaining the highest standards of quality and investing in an infrastructure to support the repeatable standards of quality is […] The post Automated Validation for all of the Apache Hadoop Ecosystem appeared first on Cloudera Blog.
 nikhil
nikhil
At Hortonworks we are constantly striving to achieve high quality releases. HDP/HDF releases are deployed by thousands of enterprises and are used in business critical environments to crunch several petabytes of data every single day. So maintaining the highest standards of quality and investing in an infrastructure to support the repeatable standards of quality is one of the key guiding principles of our organization.
Unlike traditional enterprise software, we deal with an inflow of hundreds of Apache commits, across 25+ projects in the Apache Hadoop ecosystem. Apache community has a rich set of unit tests, which are continuously run (often, for every commit) to catch regressions early. However, they are not always sufficient to assess the impact on integrated functionality. This is where having a robust, scalable and reliable testing infrastructure to validate the multi-layer stack becomes crucial.
At Hortonworks, innovation of test, build and release infrastructure is as important as delivering any new feature in HDP and the internal infrastructure has evolved into many avatars over the past few years to cater to the growing demands in the Apache Hadoop ecosystem.
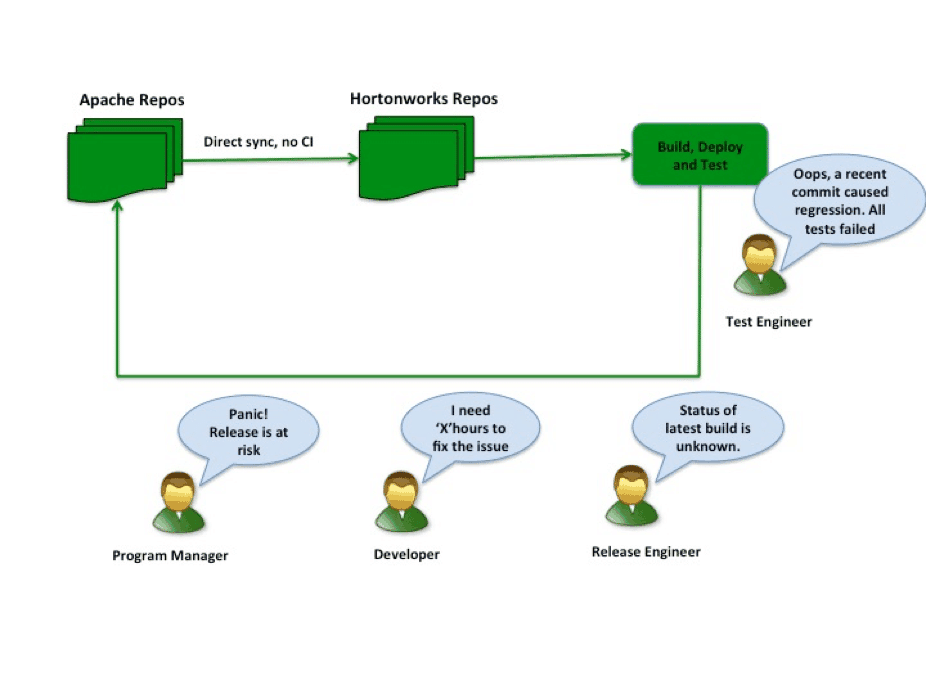
Previous Hortonworks Test Infrastructure
The problem with this approach was:
- An Apache commit was brought into Hortonworks repos directly without any pre-validations. The impact of a commit on integration scenarios was unpredictable and often caused failures.
- In case of a regression, the integration branch was left in an unhealthy state. More commits landed on an already red branch and any new regressions introduced would go untested until the branch turned green, causing further disruption.
- Enormous energy was spent in bringing the integration branch back to green every single day, leading to late cycles for scale/stress/performance tests. Late discovery of bugs in these areas potentially led to more code changes, which were again untested and possibly caused newer regressions. This cycle was endless making the release trains longer and unpredictable.
To address these issues, we implemented a phased approach, with key design principles:
- Test early and test often
- Avoid late integration
- Apache commit to first system test is instantaneous
- Apache first development and test model
- Predictable release train
Revamped Current Hortonworks Test Infrastructure
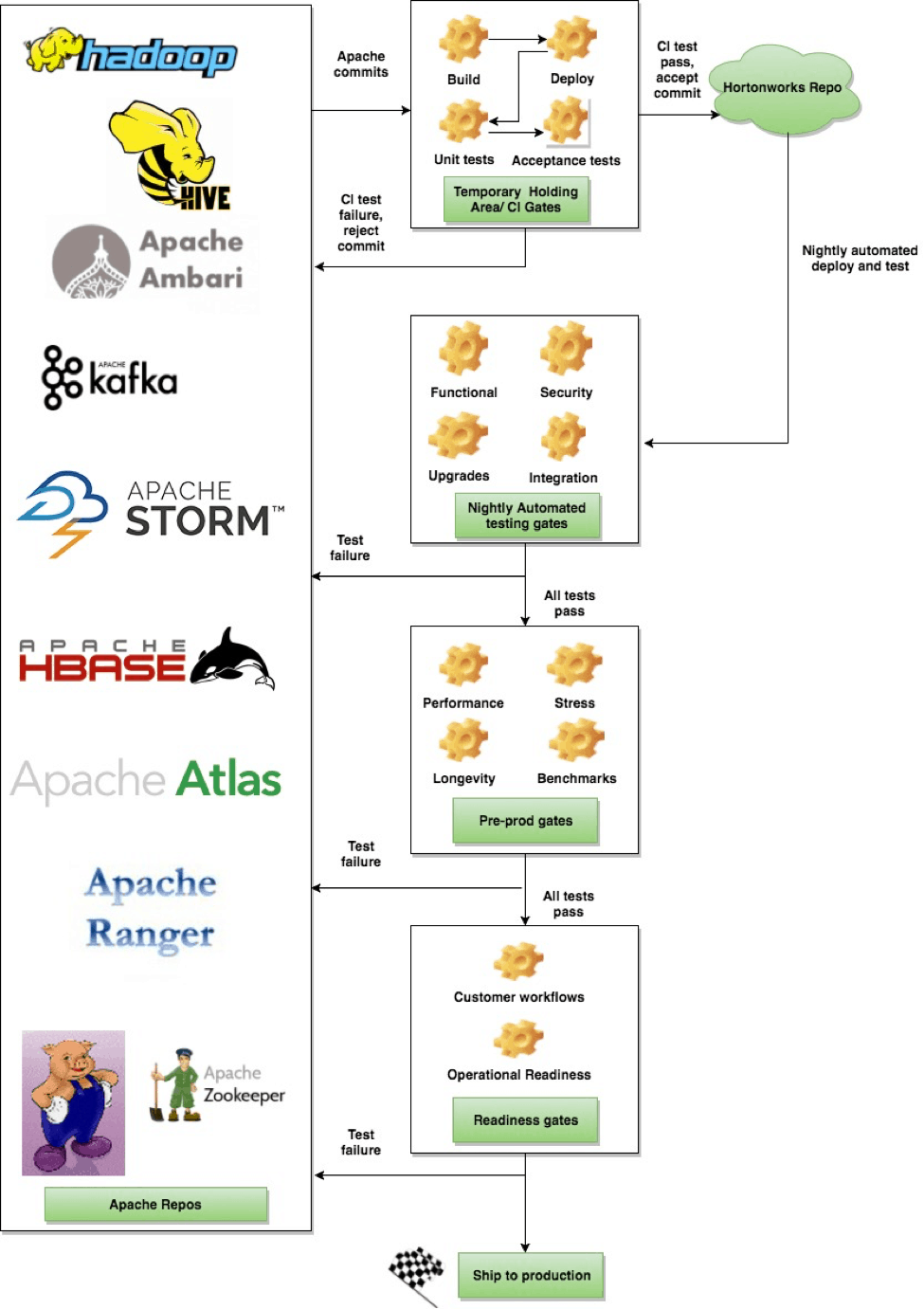
Advantages with this approach:
- Ingest of commits are streamlined and well tested – Apache commits first land in a temporary holding area until they are well tested and pass the acceptance and integration criteria.
- Feedback to developers is almost instantaneous and late discovery of bugs is prevented
- Ensures that the integration branch is always (close-to) shippable
- Apache first – We are strong believers in innovation through open source. This doesn’t apply only to new features but also to identification of issues and bug fixes. So if new issues are identified which cause test failures, they are instantly reported/addressed in Apache.
This model is proven to scale very well for point fixes. For big feature branch merges, we have a similar pipeline but the number of tests run before the feature branch merge are more exhaustive. So when the merge happens to mainline, it has already gone through thorough testing and chances of finding regressions are almost nil.
Different certification stages at a glance
Putting everything into perspective, we have a combination of:
- 4 testing environments
- CI/Staging environment
- Nightly automated testing environment
- Pre-prod
- Readiness
- 21000 compute hours, 3500 VMs and executing 30,000 tests every single day!
- Parallel HDP/HDF release trains – Major, Minor, Hotfix releases
- Multiple environments – On-premise, PaaS (HDC, HDI), IaaS on Azure/AWS
- Multiple possible test configurations – Discussed previously in introductory post
| CI | NAT | Pre-prod | Readiness | |
| Test duration | 30mins | 4hrs | 24-72 hrs | 7-10 days and continues to stay on |
| Frequency | For every commit | Once a day | 3-5 times in a release | Once a release |
| Scope | – Unit
– Acceptance |
– Functional
– Reliability – Backward compatibility – Security – Express /Rolling Upgrades – Integration |
– Perf
– Stress – Longevity – Benchmarks – Partner scenarios
|
– Hortonworks production cluster running customer workflows
– Always ON cluster running e2e scenarios simulating production workload |
| Number of tests | Hundreds | Tens of thousands | Hundreds | Hundreds |
| Compute hours | ~ 250 per day | ~ 21000 per day | ~ 2000 per release | ~ 2400 per release |
| Major Release |  |
|
|
|
| Minor Release | |
|
|
|
| Hotfix | |
|
On-demand | On-demand |
To summarize, building a scalable, reliable test infrastructure to cater to such large scale is a hard engineering problem to tackle, especially for a software stack which has unprecedented pace of innovation. In addition to having a robust process that works, we also need to allocate the right amount of compute, networking/HA capabilities, storage and develop automation tools to accommodate ongoing releases and prepare for new ones to come in future. And most importantly have the best minds in the industry who understand how the Apache community works and are continuously innovating more ways to improve the efficiency of the release process.
In our next blog, we will talk more about best practices and processes that help us test and debug efficiently (for both machines and humans). Stay tuned!
The post Automated Validation for all of the Apache Hadoop Ecosystem appeared first on Cloudera Blog.






